For over ten years, the Manchester Forum in Linguistics has brought PhD students and early career researchers from allover the world together to share their work and expertise. This year’s edition of the conference was held April 30th to the 1st of May. Thanks to the hard work of the committee and support from our funders, MFiL 2026 was a big success!
The evening before the conference, members of the committee and presenters met up to engage in some friendlycompetition! Our pub quiz was a great opportunity for everyone to get to know each other before the presentations kicked off the next day.
The conference began with a plenary talk by Dr Amy Booth titled ‘Plotting the course: Identity work and self-declaration in a dark web child sexual abuse forum.’ Following this, we held three parallel sessions which covered morphosyntax, psycholinguistics, and semantics across genres respectively. Before lunch, everyone gathered for our careers panel, where we had the chance to learn from the insights of some of our plenary speakers and the host of our research workshop. Each speaker very graciously detailed their journey to their current role and gave honest advice on navigating the job market to those in the audience.
These talks inspired many great questions and discussions which continued into lunch on day one. Already we could see the benefits of gathering linguists from such a wide array of backgrounds! Even though many of the attendees came from different institutions, and often different countries, their shared experiences with research and academia brought everyone together!
From lunch, we headed over to our first workshop of the conference where Dr Stefano Coretta taught us about ‘Open research practices.’ This was the perfect transition into our poster session, which included seven posters that dealt witha range of topics and research methods. We ended the day of presentations with Dr Simon Stein’s plenary talk ‘Effects of indexicality and iconicity on language attitudes,’ before all meeting for more exciting conversation over a lovely dinner.
The second day of the conference began with our third plenary talk. Dr Lawrence Lam presented his talk ‘Controlling overt subject in Cantonese and Mandarin: Where theory meets experiment and grammar engineering.’ We then held our second set of parallel sessions, which focused on semantics, morphosyntax, and forensic linguistics. Before ourfinal set of parallel sessions, we held our second workshop, which built on some of the discussions we had in the careers panel the day before. Dr. Sarah Ashworth from Career Services at the University of Manchester delivered an engaging careers workshop which involved advice on career planning, networking, as well as some fun interactiveactivities that allowed attendees to interact and discuss what they had learned. The final parallel sessions then involvedpresentations on phonetics & phonology, language acquisition, and communication across modalities. Last, but certainly not least, our final plenary speaker Dr Max Canzi presented on ‘Pupilometry for the study of language (and beyond).’
Thanks to continued support from the Languages Editorial Office, we were able to end the conference by presentingawards for the best and runner-up poster from the poster session. A huge congratulations to Laura Patrizzi and Mari K.Wilhelmsen for their amazing work! Following the official closing remarks, attendees gathered to celebrate a wonderful conference at the pub!
We are grateful to all the attendees for their hard work, as well as the Northwest Consortium Doctoral TrainingPartnership, the Linguistics and English Language department and ArtsMethods at the University of Manchester, andthe Philological Society for funding the conference. None of the above would be possible without you!
Three of our plenary speakers and our ‘Open research practices’ workshop presenter at the careers panel (left to right:Dr Simon Stein, Dr Lawrence Law, Dr Stefano Coretta, Dr Max Canzi).
Dinner on the first day!
Learning from Dr Sarah Ashworth at the careers workshop.
Written by Sólveig Hilmarsdóttir (Cambridge) and Dalia Pratali Maffei (Gent)
We, the organisers of the conference Sociolinguistic Variation in Ancient Languages (https://svalconference.wordpress.com/), want to thank the Philological Society warmly for their generous support of our initiative. The three-day conference took place in Cambridge on March 26-28 and it was held in the Faculty of Classics and at Jesus College.
The aim of the conference was to create and foster a conversation about the methods and perspectives needed to advance sociolinguistic approaches to ancient languages. Early career scholars in particular were encouraged to submit abstracts. We sought to focus particularly on Third Wave approaches to linguistic variation; this is a movement in sociolinguistics associated with the work of Penelope Eckert (see e.g., Eckert 2008). Work within the Third Wave has emphasised the perspective of the social meaning of linguistic variants and argued that linguistic variants are not directly correlated to social categories or a specific meaning, but that their meaning is unspecified and dynamic (Hall-Lew, Moore and Podesva 2021). One of the central concepts is the ‘indexical field’, i.e. the set of potential meanings linked to a linguistic variant (Eckert 2012). As society changes, speakers can associate new meanings with linguistic variants and, in reverse, new contexts of usage can activate new meanings, both at a conscious and at an unconscious level.
The conference programme was spread over three days and it was organised into five different thematic sessions which followed the themes of the seventeen papers we were able to accept:
*Language and Identity (Sung Min Park; Giuseppina di Bartolo and Liana Tronci; Matthew Glass; Shoni Lavie-Driver)
*Writing Practices and Social Meaning (Josh Brown; Victoria Almansa-Villatoro; Laura Nastasi; Luca Rigobianco)
*Metalinguistic Perspectives on Variation (Serena Barchi; Eleonora Cattafi; Joseph Miller; Ezra la Roi)
*Variation in Literary Sources (Agnes Vendel de Aguiar; Hung-Yun Liu)
*Registers and Language Choices (Siu Pong Cheng; Irene Chioni; Eleonora Selvi)
The programme also featured three keynote presentations which focused on different aspects of the conference theme, i.e., modern sociolinguistic theory, politeness in Latin and Greek and Greek sociolinguistics:
*Penelope Eckert (Stanford) gave the paper ‘Where does the indexical field live?’
*Eleanor Dickey (Reading) gave the paper ‘Politeness versus Classicism in Latin’
*Klaas Bentein (Gent) gave the paper ‘‘Literary’ stylization in ‘non-literary’ Ancient Greek texts: A digitally oriented, multi-modal approach
We had around 80 participants, including speakers, chairs and our two MPhil student helpers (Hanna Turi and Eleanor Jones). The conference speakers and attendees came from all over the world, from 20 countries and 50 different institutions. Most were in the room with us but several joined virtually.
The majority of the presenters were early career researchers, i.e., PhD students and postdoctoral scholars. Overall, half of the participant body was made up of early career researchers and undergraduate and master᾽s students. We were particularly pleased to be joined by so many junior academics and students.
The dialogue at the conference was vibrant throughout and featured constructive comments and questions both in the Q&A sessions as well as in informal discussions during the breaks. It was particularly enjoyable to be able to foster a dialogue between scholars from ancient world studies and scholars from modern sociolinguistics. We are grateful to Jesus College for hosting our conference dinner mid-way through the conference and to staff at the Faculty of Classics and Jesus College for facilitating catering during breaks. Several aspects of the conference were made possible through the generosity of two fellows at Jesus College, James Clackson and Véronique Mottier. In addition to the generous support from the Philological Society, the conference also received funding from the Faculty of Classics (Cambridge); Cambridge Language Sciences; The Historical Sociolinguistics Network and FWO.
We want to extend our further thanks to the members of our scientific committee who helped us review abstract and chair several of the conference sessions: Klaas Bentein (Gent); Eleonora Cattafi (Gent); James Clackson (Cambridge); Giovanbattista Galdi (Gent); Ezra la Roi (Gent); Chiara Monaco (Gent); Tomaž Potočnik (Cambridge). Finally, we are extremely grateful to Leonardo Manente who designed the conference logo.
In May 2026, I was generously awarded a Fieldwork and Travel Bursary by the Philological Society to attend SULA-TripleA. It was a four-day event which was hosted by the University of British Columbia (UBC) in Vancouver, combining the SULA (Semantics of Under-represented Languages of the Americas) and TripleA (Semantics of Languages of Africa, Asia, Australia and Oceania) conferences for the first time. There were 59 oral presentations, 15 poster presentations, as well as a thought-provoking panel on indigenous perspectives of linguistics research and language revitalisation (see programme here). The intention of the conference was to bring together researchers working on languages or dialects which are under-represented in the literature on formal semantics. Therefore, its aims align closely with my doctoral research which focuses on semantics, its interfaces with syntax and pragmatics and linguistic fieldwork on the Austronesian language, Malay (Austronesian, Western Malayo-Polynesian; Malaysia).
My presentation was based on research that was carried out as part of my PhD thesis on comparatives. The title was The Semantic Typology of Comparative Standards, Revisited. I presented original fieldwork data from Malay which provides further evidence of a two-way typology of strategies used to compose comparative meaning: compositional and pragmatic. Whilst the pragmatic strategy is dependent on the linguistic context to build meaning, the compositional strategy requires specific syntactic dependencies. I put forward three diagnostics for the pragmatic strategy and show that the comparative proper in Malay passes these diagnostics. They are: (1) wide distribution of the standard marker (i.e. outside the comparative proper), (2) (narrow and) wide readings of comparatives with syntactic islands, (3) clause boundary effects. See (1a) for a basic comparative and (1b) for illustration of the first diagnostic.
Overall, these observations lead to interesting questions and possible connections to Stassen’s (1985) classifications of comparative types, leaving exciting opportunities for future research.
The conference allowed me to share my research with a specialised audience of formal semanticists and it also enabled me to raise the profile of research on Malay, a language that, despite being widely spoken, remains under-represented in formal theoretical discussions.
Finally, I would like to sincerely thank the Philological Society for the ongoing support that they have provided to me and many other early career academics. In addition to receiving this financial assistance, I have also been fortunate enough to give a talk (entitled Comparative Constructions at the Interface between Syntax and Semantics: Lessons from Malay)at the society’s Early Career Researcher Panel in November 2024, which allowed me to refine research that has gone on to form a crucial part of my PhD thesis.
Following his publication of Benjamin Franklin, Orthoepist and Phonetician (Volumes 1 and 2), we asked author Gary German about his research process and discoveries. Congratulations Gary!
When did you first come across Franklin’s reform and what about it made you want to take on this study?
It was sometime in 2012 or 2013, while reading George Philip Krapp’s English Language in America (1925, vol. 2), that I became intrigued by his comments on Franklin’s Reformed Mode of Spelling (1768/1779). This sparked my curiosity and led me to explore the subject in greater depth.
As a variationist, when examining the proto-phonemic script Franklin devised for his RMS, I was immediately struck by the fact that he occasionally provided alternative transcriptions of the same word, forms which diverge from the general principles underlying his system. Examples include his dual RMS renderings of learnt/learn: larn’d [læɹnt] versus lɥrn [ləɹn], and perfectly: perfektlɥi [ˈpɛɹfɛktləi] versus pɥrfektli[ˈpəɹfɛktli]. The first two reflect older pronunciations characteristic of seventeenth-century English. At the same time, they correspond closely to forms attested in the rhymes of his poetry (cf. Part III, vol. 2) and, for this reason, may thus be interpreted as conservative New England features. The last two, by contrast, align not only with the internal logic of his RMS system, but also with proto-RP (i.e. late eighteenth-century London English) and, significantly, with aspects of contemporary General American pronunciation. This convergence is unlikely to be accidental (cf. question 6).
Based on this initial phase of research, I wrote an article analysing Franklin’s RMS which Professor Joan Beal (University of Sheffield) kindly accepted to read. She suggested that I submit it to the Transactions of the Philological Society. The referees of this article then proposed that I expand it into a monograph. After submitting my project proposal, one of the referees recommended that I add two levels of contextualisation, the first on Franklin’s life and times and the second on the theoretical and methodological approaches that I adopted in this book. All of Volume I (Parts I and II respectively) are devoted to these topics.
Part III of Volume 2 consists of a comparative study of the 17th– and 18th-century American and English phonology. Part IV offers a detailed analysis of the RMS and concludes that Franklin’s native accent was not the model on which his RMS was based. Part V discusses Franklin’s legacy as a phonetician. In these final chapters, I present evidence showing Franklin’s possible linguistic influence on his friend and fellow Whig, Sir William Jones. Noah Webster’s indebtedness to Franklin is clearly stated in Webster’s book, Dissertations on the English Language (1789) which he dedicated to Franklin. As such, he presented himself as Franklin’s protégé, openly stating that the RMS served as an inspiration for his own spelling reform. In the last chapter of this book, we discover that Webster’s motivations were not at all for the nationalistic reasons we generally imagine.
2. What were your biggest challenges working on this project?
One of the principal challenges – there were many – was to establish a sound theoretical and methodological framework for investigating and reconstructing the phonology of colonial American English from a variationist perspective (Part II, Volume 1). This dimension of my work arose in response to a pointed question by a reviewer for the Philological Society who asked whether the focus of my book was to be on ‘American’ or ‘British’ English. The question initially took me aback. At the time, I wondered how I would go about confidently distinguishing how the two differed during the late 18th century. Developing this aspect of the book proved immensely complex for a fundamental reason. To paraphrase Michael Montgomery (2013: 15), the early history of colonial American English phonology has not been systematically investigated since George Philip Krapp’s English Language in America (1925).
The primary objectives of Part III (Volume 2) were therefore twofold: first, to identify as precisely as possible the phonemic inventory of colonial American English and allophonic variants; and second, to reconstruct the major components of the colonial “feature pool,” particularly for Massachusetts. The ultimate aim was thus to characterise Franklin’s native Boston/Philadelphia-influenced accent. This task was both complicated and intellectually rewarding, not least because my approach, as a variationist, is grounded in a “bottom-up” conception of language (see the introduction to the Glossary of Linguistic and Sociolinguistic terminology for discussion).
To pursue this objective, and taking a cue from Joan Beal (1999), I conducted a detailed comparative phonological analysis of British and American English. This began with an examination of the pronunciations described by sixteenth-, seventeenth-, and eighteenth-century English orthoepists, alongside data drawn from seventeenth-century New England and New York town records. The latter are particularly rich in phonetic (mis)spellings of words such as ware, weer, wur, war for ‘were’; fitch, fetch, fotch, fach for ‘fetch’; lingth, lankth for ‘length’; sich, sech for ‘such’ and clooth, cloath for ‘cloth’. These variant spellings reflect a corresponding what I call a ‘phonetic range’ of competing pronunciations that were current in the colonies for any given word, each one representative of dialectal speech across broad areas of southern England.
The demographic composition of individual settlements and colonies also played a crucial role in shaping the early American varieties (cf. Chapters 11 & 12 in particular). As I have just stated, the demographic and dialectal makeup of the colonies as a whole were overwhelmingly southern English. Taking this into account, I organised these variants in accordance with John C Wells’ lexical sets, defining ‘phonetic ranges’ for each key word (Wells 1982, 1988). These competing forms can be viewed as the building blocks of early American pronunciation.
Sociolinguistic processes help explain why certain variants were retained while others receded (often into less prestigious, strictly oral, non-standard varieties), just as in England itself. The seventeenth-century American data examined here correspond closely not only to the descriptions of early English orthoepists, thereby confirming the transmission of dialectal features to the New World, but also to nineteenth- and, to a striking extent, twentieth-century dialectal pronunciations recorded in Great Britain, Ireland, and North America.
A second major challenge lay in the analysis of over 3,000 lines of Franklin’s poetry. To my knowledge, his poems have never previously been studied from a linguistic perspective. This corpus proved to be an immensely rich source of evidence indicating key aspects of his natural ‘American’ pronunciation, an accent that, in many respects, appears close to that of rural southeastern England. To guard against interpretive bias, I analysed the rhyme schemes of over 6,000 lines of poetry by two younger New England poets, Timothy Dwight (Massachusetts) and Joel Barlow (Connecticut). The results showed that their rhyme patterns were extremely similar, often identical.
The findings were both fascinating and perplexing. While 80–85% of the rhymes are “perfect,” 15–20% are “imperfect” when judged against modern RP or General American pronunciation. These imperfect rhymes fall into two main categories: front mid vowels and a wide range of back vowels. The former can be quite easily explained in terms of the Great Vowel Shift. The latter are more problematic, as illustrated by pairs such as blood ~ God, food ~ flood, come ~ home, cup ~ shop, coast ~ cost, sun ~ moon, and road ~ wood (cf. Chapters 20, 21 and 22, Vol. 2, for analysis).
Not only do Franklin, Barlow, and Dwight share these patterns, but they are also attested in English poetry (e.g. Alexander Pope, Robert Herrick, and indeed as far back as William Shakespeare and John Donne). For example, like Franklin, Shakespeare rhymes sun with moon (in his first poem, ‘Venus and Adonis’, 1593). Such correspondences are supported by observations of seventeenth-century orthoepists and by spelling evidence in colonial records. Notably, and to repeat, many of these features persisted into the nineteenth and even late twentieth centuries (e.g. Webster 1789, Wright 1898, 1905; Grandgent 1899; Whitehall 1941; Orton & Deith 1962–1971; Hall 1942; Avis 1971; Shorrocks 1998; Trudgill 2016). A feature known as ‘New England short o’ provides us with important clues to solve this puzzle. To my knowledge, no previous study has systematically integrated British and American data in this way.
What, then, is the broader significance of these findings? As noted above, the aim was to determine whether Franklin’s native pronunciation corresponded to the proto-phonemic system he proposed in his RMS. The answer is an emphatic ‘no’. Born in 1706, Franklin’s accent derived primarily from late seventeenth- and early eighteenth-century Boston English, itself shaped by earlier seventeenth-century settlement patterns. An estimated 69% of Boston’s settlers were of East Anglian origin, particularly from Suffolk, as well as from Essex and the London area more broadly (Fischer 1989). The Boston variety emerged from this demographic mix. His subsequent residence in Philadelphia – where approximately 80% of Quakers there were from the Northwest Midlands – may also have reinforced a few detectable traces in his speech (see Part III, Volume 2).
3. Why do you think it is that Franklin’s reform has not been studied in depth until now?
Several factors may account for this. First, Franklin’s Reformed Mode of Spelling is a very short treatise – barely fourteen pages – published as the final chapter of Benjamin Vaughan’s edition of Franklin’s Political, Miscellaneous, and Philosophical Pieces (London, 1779). Its brevity alone gave the impression that it was a hastily conceived work and, for this reason, has discouraged sustained scholarly interest. Indeed, in the same vein, the work is clearly incomplete. Franklin evidently intended to devote more substantial and systematic effort to its treatment. For instance, Vaughan himself notes that Franklin provides only a single full description of the PRICE diphthong, followed by a large blank space, strong evidence that he planned to include further analyses of other diphthongs.
Sadly, he never completed his treatise, the most plausible explanation lying in his political engagement at the time. When he drafted the initial version of the RMS in July 1768, he was serving as an agent representing the interests of several North American colonies in London. As a Whig, he was deeply involved in contesting the policies of the Tory establishment, including the House of Lords and the King’s Privy Council, particularly with regard to colonial legislative rights which, he argued, were grounded in the English Bill of Rights (1689). These responsibilities almost certainly diverted him from completing the treatise.
To return to your question, Franklin’s RMS has in fact attracted intermittent attention from linguists, beginning with Noah Webster (1789) and continuing with figures such as Alexander John Ellis (1869), Charles Grandgent (1899), George Philip Krapp (1925), Kemp Malone (1925) and Charles Wise (1948), among others. However, these contributions are typically limited to short articles (often three or four pages) or scattered observations within broader works. The topic has never generated sufficient momentum to warrant a full-length monograph. Of these scholars, Wise’s 21-page study remains by far the most substantial and insightful analysis to date.
Although most scholars have regarded Franklin’s reform as ‘interesting,’ many have dismissed it as incomplete, unwieldy, or even unintelligible (Isaacson 2003), largely because of his unconventional alphabet, which includes six newly devised characters. While such criticisms are understandable, they have obscured two crucial points: first, the diachronic and sociolinguistic significance of the variant transcriptions (of the kind discussed above in question 1), and second, the genuinely innovative character of Franklin’s system – particularly his intuitive grasp of concepts such as the phoneme (over a hundred years before it was theorised) and his deep understanding of articulatory phonetics (see Chapters 25–28 of Part IV, Volume 2). His scheme for transcribing the English vocalic system is essentially the same as that adopted by the International Phonetic Alphabet in 1886! These achievements have been overlooked by scholars.
Finally, the relative neglect of the RMS since the mid-twentieth century can be partly explained by broader shifts within linguistics itself. From the 1950s and 1960s onward, scholarly attention increasingly turned to the role of non-English influences on the development of American English, especially in the context of large-scale immigration during the eighteenth, nineteenth and twentieth centuries. This shift is reflected in the amount of research on African American Vernacular English, as well as on postcolonial Englishes, world Englishes, and creolistics, fields in which the emphasis is placed on mixed linguistic origins. From an academic perspective, this reorientation has been both necessary and productive, especially because such areas of research had previously been neglected and even purposefully marginalised. At the same time, it represented, in part, a corrective to the strongly Anglo-centric perspectives that had dominated nineteenth- and early twentieth-century scholarship. One unfortunate consequence, however, has been a relative decline in interest in and even downplaying of British English influences on the formation of American English. The present study seeks to redress this imbalance by offering what may be the first detailed comparative analysis of British and American historical phonology from a variationist perspective (Part III, Vol. 2).
4. What was it like working with the archives and manuscripts? Can you talk us through how you accessed these?
Quite honestly, while examining the Franklin papers at the American Philosophical Society Archive around 2016 or 2017, I came across – almost by chance – the first manuscript letter that Benjamin Franklin wrote to Polly Stevenson on 20 July 1768. Accompanying this letter was a full table in Franklin’s hand presenting a complete consonant and vowel inventory, including all the characters of his newly devised orthographic system, as well as descriptions of each sound.
The system was based on the principle of “one letter for one sound,” an idea inspired by Thomas Smith’s De recta et emendata linguae Anglicae scriptione (1568), a source with which Franklin was clearly familiar (cf. Question 5 below). This point has never been recognised previously. Smith is generally regarded as the father of English orthoepy. The July 20 letter is therefore of exceptional importance for several reasons.
First, unlike the September 26th and September 28th letters exchanged with Polly Stevenson in 1768 (entirely written in the new RMS script), and which were later published in Benjamin Vaughan’s 1779 edition of Franklin’s writings, this July 20th letter has never been studied from a linguistic perspective and was only brought to scholarly attention by William B. Willcox (1972), whose work I was unfamiliar with at the time of my discovery.
Secondly, as this was Franklin’s first attempt to use his newly devised alphabet, the letter contains numerous transcription errors, many of which he corrected in situ. Others reveal inconsistencies in pronunciation and for this reason, as noted earlier, provide valuable evidence about his New England accent (see Part III).
Thirdly, it is in this letter that Franklin explicitly asks Polly Stevenson to help him determine whether the phonetic characters he had selected for his proto-phonemic alphabet accurately represented ‘polite’ English pronunciation. This single remark proved crucial to developing my working hypothesis: namely, from the outset, Franklin’s objective in developing the RMS was to provide speakers across the British Empire – most of whom were dialect speakers – with a model of pronunciation based on what he perceived to be cultivated London English. This interpretation challenges long-standing views that his RMS was based on his native Boston accent. It also reveals that assertions regarding the similarities between colonial American English and ‘polite’ London speech have been somewhat exaggerated (cf. Chapters 10 through 12, Vol.1).
This conclusion is reinforced by Polly Stevenson’s personal role in this endeavour. As a young, highly educated (lower?) middle-class speaker from Kensington, London, she was Franklin’s close friend, correspondent and collaborator. Her role provides one of the clearest indications of Franklin’s pro-English, heteronomous vision of the English language. This deduction is also supported by Franklin’s early fascination with the Spectator (cf. (cf. Chapter 2 of Part I) not to mention a letter to Hume (1760) in which he states that the linguistic model for America should be the ‘best English’ of England (cf. Chapter 14, Volume 1).
Another crucial source I examined was Vaughan’s 1779 Political, Miscellaneous, and Philosophical Pieces (London), in which the final chapter presents Franklin’s Reformed Mode of Spelling. Although the 1768 manuscripts preserved in the American Philosophical Society Archive and this 1779 printed version are virtually identical, there are a number of significant differences which I analyse in Part IV (Chapters 26–27). These include, for example, Franklin’s hesitation (in his 1768 vowel and consonant table) between competing pronunciations, such as [ɒi] versus [ʌi ~ əi] in defining his PRICE diphthongs. This suggests his uncertainty as to which form carried greater prestige, underscoring the importance of Stevenson’s input. This also provides very early evidence that [ɒi] was already present in London speech as early as 1768 (as it still is today, cf. Orton and Tilling 1970).
Finally, these sources bring to light a previously underappreciated fact: Polly Stevenson’s significant role in the development of this orthographic project. This relative neglect is not due to Franklin, who refers to her as his ‘partner’, but rather to later scholarship. In a little-known letter to Franklin dated 1775, Stevenson refers to ‘our alphabet,’ thereby confirming that she regarded herself as an active collaborator in the enterprise.
For the first time, readers are able to consult digitised versions of these two manuscript sources (see Appendices 1 and 2). This study is also the first to provide a systematic transcription of Franklin’s and Stevenson’s RMS letters into the IPA. In addition, each lexical item is included in a 442-word glossary with IPA equivalents (see Appendix 3).
5. What was the most surprising finding you encountered in the materials you worked with?
Frankly, the findings are too numerous either to enumerate or to rank. One of the most significant, as noted above, is that Franklin’s RMS scheme was heteronomous, that is, modelled on what he imagined to be sophisticated London English. Given the considerable diversity of accents in England at the time, this was an inherently challenging task for a provincial speaker such as Benjamin Franklin, and this helps to explain his reliance on Polly Stevenson’s opinions on the matter. Even in London, there was no ‘fix’d’ pronunciation of English, as both Polly Stevenson and Samuel Johnson emphatically stated at the time.
A second, equally important finding is that Franklin’s native pronunciation was the product of a New England koine (with multiple registers) which, in many respects, was very close to contemporary southern rural English dialects. For example, MEAT words were still realised as [ɛː ~ e̞ː] by Franklin and educated his fellow New Englanders, rather than [iː], which is the value Franklin consistently promotes in his RMS. This raising of [ɛː] to [iː] was a relatively recent innovation originating in lower-status 16th century London speech, and one that had been regarded as ‘vulgar’ in the seventeenth century. For that reason, the fact that this innovation was being resisted by many 18th-century middle-class speakers in the colonies can be viewed as an early instance of ‘colonial lag’.
By identifying the principal features of seventeenth- and early eighteenth-century New England pronunciations, I was able to show that the occasional transcriptional ‘slips’ mentioned earlier are best understood as unconscious reversions to Franklin’s native Boston speech. Many of these forms disrupt the internal consistency of his system and, to my knowledge, have not previously been identified or discussed (see Chapter 28). This interpretation is supported by Franklin’s linguistic background: born in 1706, his father and older siblings were from Northamptonshire and emigrated to Boston in 1683. His mother’s parents were from Norfolk and settled in Watertown, Massachusetts, in 1635. The diachronic evidence presented in Part III (Vol. 2) suggests that Franklin’s idiolect remained, in phonological terms, closer to these seventeenth-century English inputs than to late eighteenth-century London English, and therefore quite distant in certain respects from the innovative model he proposed in his RMS.Lastly, one of the most intriguing discoveries was the extent to which key aspects of Franklin’s RMS were anticipated by and inspired by the work of sixteenth- and seventeenth-century English orthoepists such as Thomas Smith (1568) and very probably John Hart (1569). Franklin was certainly familiar with the work of John Wallis (1653) and had studied John Wilkins’ An Essay Towards a Real Character, and a Philosophical Language (1668) in detail when he was only sixteen (see Chapter 13, Volume 1). The degree to which he relied on the work of early English orthoepists (but not 18th century orthoepists!) has never been realised until now (see also Mazarin 2020).
6. What insights can we gain into the phonology of early American English from Franklin’s reform? How different is it from today’s American phonology?
Somewhat paradoxically, contemporary General American (GA) is, in broad terms, closer in several respects to late eighteenth-century cultivated London English than is English Received Pronunciation (RP). Proto-RP (c. 1780–1800) shared a number of features with present-day GA, for instance, the preservation of:
postvocalic /r/, although it was already weakening in London English (and New England) (cf. John Walker, 1791);
/æ/ [æː ~ ɛː] in words such as past, bath, half, draft, chance. Current RP [aː ~ ɑː] pronunciations were considered ‘vulgar’ at the time;
/ɑː ~ ɒː/ in words such as taught, thought, law, so typical of American English today. On the other hand, /ɔː/ was introduced into RP English in 1917 by Daniel Jones (cf. Mazarin 2020). This suggests that American /ɒː ~ ɑː/ in these key words represents a very conservative pronunciation. Note that both English orthoepists, John Wallis, John Wilkins and Franklin, give fall ~ folly as minimal pairs differing only in the length of the vowel.
monophthongal /o̞ː/ (with some variants) which later developed into /oʊ/ in both GA and RP during the nineteenth century (now RP /əʊ/). However, there are strong indications that Franklin may also have pronounced both know and now as [əu]. Note that in the Tidewater region of Virginia words such as boat, know, about, are commonly realised as [əʊ].
Interestingly, in certain respects, the RMS goes a step further than would be expected. Notably, Franklin systematically centralises <er> in words such as mercy and perfect, at a time when the cultivated pronunciation in both America and London appears to have been [ˈmɛɹsi] and [ˈpɛɹfɛkt]. The evidence demonstrates that [ˈmæɹsi] and [bæɹθ] ‘birth’ were also common in America (Duponceau 1818), whereas the centralised form [ˈməɹsi], now standard in GA, was then associated with lower-status speech in the colonies. Yet, according to Duchet & Trapateau (2019), [əɹ] was apparently more acceptable in London than [æɹ]. This points to an early sociolinguistic divergence between the developing British and American norms.
Franklin’s choice of this centralised variant for his RMS is therefore somewhat puzzling, especially if, as the evidence in Parts III and IV suggests, he himself retained [ɛɹ] in his own speech. Two possible explanations present themselves: either he did not perceive centralisation as socially marked, and/or Polly Stevenson’s pronunciation may have influenced his judgement (in favour of [əɹ]) – perhaps reflecting features of her (lower-?) middle-class London speech. If so, this might indicate that centralisation was more widespread among educated Londoners during the 1760s and 1770s than has generally been assumed. Note, however, that the New England town records show that centralisation, along with other stigmatised features such as r-loss, was part of the colonial feature pool during the 17th century.
In sum, the RMS represents an attempt to establish a model of cultivated London English (proto-RP) that was not yet codified. As seen above, a fair number of features of proto-RP have been more faithfully preserved in contemporary General American English. By contrast, RP has since incorporated features that were formerly associated with socially stigmatised varieties of London speech. These innovative features were presumably introduced under the influence of a rising new middle class composed of wealthy artisans and merchants, that is, people sharing the same humble origins as Franklin himself.
7. If Franklin’s reform had actually been adopted, what do you think the long-term impact on English literacy or global English might have been (if any)?
Benjamin Franklin rightly argued that language is in a constant state of flux, and it was on these grounds that he advocated a phonologically based orthography (although the concept had not yet been theorised). In his view, this would have drastically reduced the time required for people having little or no access formal education to learn to read and write. As he noted in his letter to Polly Stevenson of 28 September 1768, literacy might be acquired in a matter of weeks rather than years. At the same time, Franklin was fully aware that such a system would require continual revision, as new pronunciations emerged and older ones fell into disuse.
He maintained that when orthography ceases to correspond to contemporary pronunciation, words risk becoming mere ‘things’, that is, symbols devoid of phonetic substance (as in through, though, thorough, enough). From his perspective, therefore, no permanent, static, spelling system could be justified. For example, his London-influenced representation of the PRICE and CHOICE diphthongs (London ɥi /ʌi/, as opposed to his native Boston [əi ~ ɤi]) would eventually have required modification to forms closer to modern RP and General American /aɪ/ and /ɔɪ ~ o̞ɪ/ respectively. In short, the RMS would have necessitated periodic updating in line with the most prestigious London pronunciations of the time.
Had such a system been adopted, it would likely have produced a far more transparent, consistent, and learnable orthography, with clear pedagogical benefits. It is important to recall, however, that Franklin imagined his 1768 reform would be adopted by all the subjects of the British Empire, of which the American colonies were then an integral part. In this respect, the broader historical context is crucial: had the American War of Independence not occurred, a war he struggled with such energy to avoid (cf. Chapters 6-9, Part I), it is almost certain that middle-class British and American pronunciations would have remained more closely aligned than they are today.
Franklin’s position must also be understood in light of his political and cultural outlook. Many Americans forget that, for most of his life, Franklin was passionate British imperialist who fought strenuously to convince the King’s officials in London that America’s role in the Empire would guarantee England’s economic and geopolitical dominance for centuries to come. From this perspective, his preference for London English as a linguistic model for all English speakers is entirely consistent with his broader intellectual and political commitments.
Both volumes are now available to access for free at the links in the banner.
The organising committee of the 23rd Old-World Conference in Phonology (OCP23) wishes to record its gratitude to the Philological Society for its support of the meeting, which took place in Cambridge from 13 to 16 January. The conference brought together speakers and participants from across the international phonological community to discuss contemporary research in the field.
The programme commenced on 13 January with a workshop at the Provost’s Lodge, King’s College, focused on foundational questions regarding phonological representation and its computational consequences. The sessions addressed the structural form of representations—including linear strings, autosegmental tiers, and hierarchical configurations—and the relationship between representational choice and analytic complexity in phonological modelling. Discussions drew on specific phenomena, such as feature-spreading, to examine how theoretical assumptions shape both descriptive analyses and computational frameworks.
The main conference was held in the Bateman Auditorium at Gonville and Caius College, following welcoming remarks from Professor Brechtje Post and Professor Bert Vaux (University of Cambridge) on 14 January. The three-day programme comprised 41 oral presentations, and 46 poster sessions covering a diverse range of topics, including:
Segmental and prosodic structure
Tone and intonation
Morphophonological patterning
Phonological learning
Theoretical and computational approaches to sound systems
The invited programme featured two keynote presentations that provided both historical and theoretical perspectives on the discipline:
Professor Pavel Iosad (University of Edinburgh): Presented a reflection on the development of phonological theory, revisiting the Jakobsonian inheritance through the lens of Slavic phonology. The talk argued for a more pluralistic understanding of the intellectual lineage of generative phonology.
Dr Patrycja Strycharczuk (University of Manchester): Examined phonological representation and sound change using a gestural model of vowel structure. The presentation explored the distinction between true monophthongs and pseudo-diphthongs and its consequences for phonetic realisation and diachronic change.
Poster sessions provided an essential space for the discussion of work in progress, facilitating exchange between researchers at various career stages. Formal sessions were complemented by sustained discussion during breaks and a conference dinner held in the Gonville and Caius College dining hall. These interactions highlighted a shared engagement with foundational questions of representation and empirical evidence, marking a successful iteration of the OCP series.
The conference attracted an audience of approximately 150 people, including both in-person attendees and those participating remotely via Zoom. The event’s geographic scope was extensive, featuring contributors from over 50 academic institutions across 18 countries and territories. This diversity facilitated a broad international exchange, drawing together researchers from across Europe, North America, and Asia.
Written by Fae Hicks (University of Edinburgh), recipient of a travel and fieldwork bursary from the Philological Society.
Thanks to the support of PhilSoc’s Travel and Fieldwork bursary I was able to present my research, The myth of phonetic erosion: grammaticalisation, causality, phonology and syntax, at the International Conference of Historical Linguistics (ICHL) in Santiago de Chile from the 18th – 22nd of August.
ICHL brings together researchers in Historical Linguistics from all areas of the field encouraging discussion between data driven linguistics and both formal and functional theorists alike. The conference facilitates discussion between theoretical silos which in turn promotes an environment where researchers are encouraged to challenge the assumptions of their own frameworks and methodologies. As the largest conference in Historical Linguistics, ICHL was the ideal venue for me to present my research and meet other historical linguists thus beginning to establish myself in the field.
At ICHL I presented a talk written in collaboration with my supervisor, Patrick Honeybone, investigating the conception ‘phonetic erosion’ in Historical Linguistics, arguing that the uses of the term are so disparate that it cannot possibly mean anything phonologically and is instead characterised by its supposed link to grammaticalisation. We went on to argue that there is no clear causal link between erosion and grammaticalisation which makes the term ultimately meaningless. The content of this presentation pertains to the first section of my PhD which questions the purported relationship between phonological and syntactic changes in grammaticalisation processes. In the ICHL talk I highlighted a need for precision and clarity in the use of terminology within the field and questioned the causal link between phonological and syntactic change presenting a number of open questions for the field such as:
If we except that they are useful concepts, where does grammaticalisation end and erosion begin?
How close (in time) do two changes have to be for there to be causal relationship?
How do we extract the proposed ‘cause’ from the rest of the historical context?
The ICHL talk sets the stage for the rest of my PhD where I attempt to address such questions with particular focus on the notion of causality and historical process – i.e., what must be true in order for us to say that one change ‘caused’ another and how far back can we trace cause.
Presenting this, somewhat controversial work, at ICHL sparked informative conversations with people working in various branches of Historical Linguistics providing me a number of fresh perspectives that I will bear in mind going forward. Moreover, several audience members have said that my argument encouraged them to reflect on their own usage of the terms – thus, I hope that sharing my presentation at ICHL has had some non-zero impact of the field of Historical Linguistics.
I am incredibly grateful to the Philological Society for their travel bursary without which none of this would have been possible! This bursary came at a crucial time for me, as ICHL is a biannual conference this was the only time it is happening during my PhD and as the largest conference in my field it was vital that I attend, but I would not have been able to finance a trip to the Southern Hemisphere without PhilSoc’s generous support.
In the depths of Scottish winter, 1st – 2nd December, we welcomed over 50 Historical Phonologists to Edinburgh for the 7th Edinburgh Symposium in Historical Phonology (ESHP). ESHP is a biannual event that brings together researchers from across the world for a “Historical Phonology party”. As it is a small subfield, events like ESHP are vital to promote and maintain a sense of community within Historical Phonology and we are very grateful to the Philological Society for supporting this event. Thanks to funding from PhilSoc we were able to keep conference fees low and offer a reduced rate to student attendees.
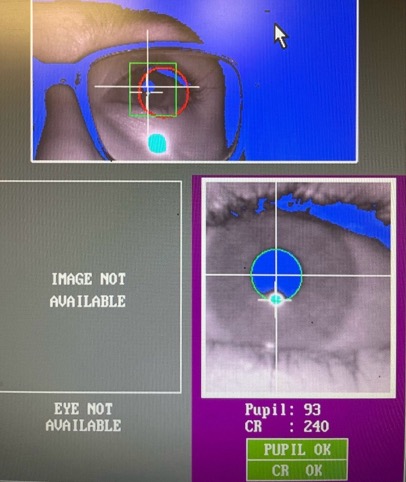
ESHP carves out space to consider the big issues, those overarching questions which guide research in Historical Phonology but are too complex to capture in a twenty-minute talk, like what is a possible phonological change? How can the results of historical phonology inform phonological theorising? And to what extent is phonological change independent of changes that occur at other levels of the grammar? Over two hours (on different days!) our plenary speaker, David Natvig, dove into these latter questions in his talk “Phonology Down and Phonology Up: Historical Phonology at the Interface with Phonetics and Morphology” which explored the key questions of when phonology actually changes and how we can know that it has changed, in part focusing on case studies of vowel shift and velar palatalisation from the history of Norwegian.
As always, talks at ESHP covered a wide range of topics and methods of investigation from the reconstruction of Hittite stress to experimental phonetic approaches to accounting for sound change. Split across both days, the poster sessions are central to ESHP’s calendar. The poster sessions in particular promote active discussion between attendees at all career stages. We are grateful to the ESHP community for making this not only an intellectually stimulating and entertaining event, but also a familiar and welcoming one. Of course, we are particularly thankful to PhilSoc for enabling us to keep ESHP an accessible event.
Written by Sophie Krol (UCL), a recipient of the Philological Society’s Master’s Bursary 2024-25
It is thanks to the Philological Society and their extremely generous Master’s bursary – and to my supervisors at Newcastle University who brought my attention to the bursary in the first place – that I find myself at the end of an enriching twelve months at UCL.
Wilkin’s Building, UCL
As a Linguistics undergraduate at Newcastle (2021-24), I became enthused by topics that hadn’t occurred to me before – from syntactic theories attempting to account for spoken and signed languages alike, to my extended study on relative-clause attachment ambiguity, to the questions of evolutionary linguistics – so much so that I didn’t feel I was done yet.
Spurred on to pursue further study, I came across UCL’s MSc in Language Sciences. Of its five specialisations, one intrigued me the most: sign languages and deaf studies. This was especially the case given its Deafness, Cognition and Language research centre (DCAL), the source of widely impactive research on British Sign Language (BSL) and deafness. Their research areas span neuroplasticity, cross-modal machine translation, and attitudes towards BSL’s significant regional variation, to mention a few.
This specialisation opened doors to learn directly of the rich and diverse deaf culture and community that stands on the shoulders of the likes of Francis Maginn and Helen Keller. In particular, this was made possible by the BSL Level 1 module led by Clive Mason, and the DCAL-specific Psychology and Language Sciences (PALS) modules.
For my Deafness, Cognition and Language module, I chose to present research on the learning of numeracy and mathematics, specifically the attainment gaps commonly observed between D/deaf and hearing peers. The research seemed to repeatedly lead back to one main factor: language deprivation. Devastatingly common in the deaf community – but importantly, avoidably – language deprivation happens when a child misses out on being exposed to a fully-accessible (often, signed) language during their early years. This can have profound, long-term effects that extend well beyond language itself.
My programme culminated in a research project within the Experimental Psychology division – specifically, a psycholinguistic investigation into lexical ambiguity. Broadly speaking, I aimed to inform the research base on factors capable of enhancing reading fluency and efficiency. 75 participants were semantically primed by reading sentences including words that have multiple meanings (homonyms). Crucially, contextual information disambiguated these words towards their less common meanings – take the bird-related meanings of swallow or crane as examples. I manipulated whether this disambiguating context varied or whether it was identical for each exposure of the given homonym.
Setup of the Eyelink 1000 tracker
To allow me to examine whether repetitive or variable priming better facilitated readers in accessing infrequent meanings, I used the eye-tracking method. I found that, when previous exposure to a word meaning had occurred in variable contexts, the appropriate meaning would be more likely to be accessed faster (as assumed from faster reading times) upon a next encounter.
Having gained so much from my time here at UCL, I am immensely grateful for the PhilSoc’s Master’s bursary, as well as those that supported me in applying for both the bursary and the course itself.
We are delighted that the first open-access monograph of the Publications of Philological Society was published last month by Open Book Publishers. The monograph, entitled Grammar of Etulo: a Niger-Congo (Idomoid) Language by Chikelu I. Ezenwafor-Afuecheta, is available to read online or to download in PDF format free of charge.
In this post, we had to chance to speak to Chikelu and ask her about her experience of researching and writing the grammar. Thanks very much to Chikelu for her thoughtful responses.
How did you first come into contact with this language and what drew you to study it?
Nigeria is home to numerous minority languages, many of which face varying levels of endangerment; one of these is the Etulo language. I first encountered Etulo back in 2010, while doing a Master’s program in Linguistics. One of my classmates had spent her compulsory youth service year living among the Etulo community in Benue State. I was looking to focus my MA thesis on a minority language, and meeting her and through her being introduced to the Etulo community in Buruku Local Government Area, Benue State, greatly influenced my choice of Etulo. Moreover, Etulo fits a textbook case of a severely endangered language: it’s not taught in schools or used for instruction, it lacks a codified standard, and is only used in everyday home and marketplace conversations in Etulo-speaking areas, where it exists alongside stronger languages like Tiv.
What kind of data did you work with when compiling this grammar? Can you talk us through the process of collecting this?
My research relied entirely on linguistic field data gathered through direct elicitation from native language consultants between 2014 and 2023. The Etulo speakers I worked with are trilingual, fluent in Etulo, Tiv, and partly English. Generally, most Etulo speakers in Benue State are bilingual, speaking both Etulo and Tiv, with Tiv being the dominant local language in the area.
To establish the phonemic inventory of Etulo, I made use of the Swadesh wordlist, Blench’s (2008) comparative wordlist, and the SIL Comparative African Wordlist (SILCAWL), which contains 1,700 lexical items. For morphological analysis, I employed Štekauer’s (2012) questionnaire on word formation processes. Additional syntactic data were obtained using questionnaires from the Max Planck Institute for Evolutionary Anthropology, including Klamer’s (2000) valence questionnaire, the relative clause questionnaire developed by members of the Bantu Psyn project (University of Berlin and Université Lyon, 2010), and Hengeveld’s (2009) questionnaire on complement clauses.
I also used picture-based tasks to elicit data on tense and aspect, as well as narrative and folktale materials to complement the dataset.
How did you decide what to include/exclude, and the order of the chapters?
Before beginning the main phase of my research, I reviewed published grammars of both African and non-African languages to gain a foundational understanding of how grammatical descriptions are structured. Dixon’s Basic Linguistic Theory (Volumes 1–3) was especially useful in guiding the development of my initial set of fieldwork questionnaires.
Data collected during fieldwork later helped refine and narrow down which linguistic features were relevant for inclusion in the Etulo grammar. In certain cases, grammatical categories featured in the questionnaire such as gender or noun class distinctions were not attested in Etulo, and thus were excluded. Conversely, some features, like tone polarity, which were not initially part of the questionnaire, were incorporated into the grammar after being identified as salient in the data.
In essence, the structure of the Etulo grammar was initially influenced by existing grammatical prototypes of African languages and by Dixon’s theoretical framework, but was continuously adapted based on empirical evidence from Etulo. The chapters were organized from the smallest level of linguistic analysis (phonology) to the largest (syntax).
Did you find any features of the language that you weren’t expecting, or that presented a descriptive challenge?
In the course of describing Etulo grammar, I encountered a few analytical challenges—two of which are particularly noteworthy.
The first challenge concerned the Etulo phoneme inventory, specifically the analysis and representation of certain vowel sequences such as [ie, ɪʊ, ɪɔ, io, ia, ɪa, uɛ, ue, ua]. The key question was whether these should be treated as glides (/j/, /w/), as diphthongs (single vowel units), or as non-identical vowel sequences that can each carry tone. Earlier work on Etulo by Armstrong (1974) interpreted these sequences as glides, thereby introducing additional phonemes like gy andky into the inventory.
However, this approach presents a problem: it unnecessarily expands the phoneme inventory, violating the principles of economy and pattern consistency, since these vowel sequences can occur after many consonants in Etulo ( ky, gy, fy, by, my, tsy, bw, fw, tsw, mw as in kye gya bwa fwa.) and as single vowel sounds. Moreover, analyzing them as glides overlooks the fact that the vowels in these sequences often exhibit tonal contrasts that remain distinct. Nor could they be treated as diphthongs, as each vowel in a pair can independently serve as a tone-bearing unit. Consequently, I opted to analyze them as non-identical vowel sequences capable of bearing either identical or contrasting tones.
The second challenge involved the internal structure of Etulo verbs. Many verbs in Etulo require a noun to co-occur with them as a meaning-specifier, a feature typical of several West African languages. The semantic bond between the verb root and its nominal complement is often so tight that native speakers perceive some verb-noun combinations as single lexical items. This perception may also be reinforced by phonological processes such as vowel elision and contraction, which are frequent in rapid speech. For instance, the verb ʃí áʃí ‘to sing’ is often realized as ʃáʃí after elision of the verb’s final vowel.
The main difficulty, therefore, was distinguishing the verb root from the noun complement. In cases where this distinction was unclear, I relied on syntactic tests specific to Etulo, such as constructions involving noun fronting and verb-root reduplication, to identify the true verb root.
Why do you think language documentation is so important?
Language is far more than a marker of identity. It is an essential part of culture, the embodiment of a people’s values and knowledge, and the vehicle by which culture is communicated and handed down from one generation to the next. In an era when identities, languages and cultural traditions are vanishing, the task of preserving what remains becomes crucial: through documenting folktales, fading vocabularies, cultural rituals, proverbs, or grammars, we safeguard not just words but the depth of a civilization, the sense of self and community that once felt both sacred and enduring.
If someone wanted to learn more about Etulo and other Niger-Congo languages, where would you direct them?
The Niger-Congo language family is a vast phylum made up of numerous subgroups, some of which are more developed than others. For example, the Igboid and Yoruboid groups, both spoken by millions in Nigeria are relatively better documented and developed, despite also facing endangerment. In contrast, the Idomoid subgroup, which includes minority languages such as Idoma, Yatye, Akweya, Akpa, Eloyi, Igede, Alago, and Etulo, remains far less developed.
While it is easy to find grammar books, online learning materials, and university programs dedicated to Igbo and Yoruba, the same cannot be said for Idomoid languages. Regarding Etulo specifically, its development has not yet reached the point where learners can readily access structured online or physical resources for language learning. However, the Nigerian Bible Translation Trust, in collaboration with some Etulo speakers, has developed an orthography proposal and translated parts of the New Testament into Etulo. There is also a historical account of the Etulo people written by Tabe (2007), along with a few other published studies available online.
Beyond publishing a grammar of Etulo, it is clear that the language requires comprehensive documentation of its cultural heritage. This realization has motivated my current collaboration with members of the Etulo community to develop a proposal aimed at recording Etulo folktales and proverbs, many of which are rapidly disappearing under the growing influence of Tiv, the dominant language and culture in Benue State, Nigeria.From my personal experience, the Etulo people were consistently warm and welcoming, and it was a genuine pleasure to collaborate with them in producing the grammar of the Etulo language. While this work is not without its imperfections, it nevertheless establishes a solid foundation for future teaching materials and further linguistic research on Etulo and other languages in the Idomoid languages subgroup.