by Mari Aigro (University of Tartu)
Seeing grammaticalisation as being analogically driven takes the explanatory power, which is frequently assigned to syntactic position, and assigns it to the semantic analogy between the source and the target. This case study focuses on the semantic cohesion patterns in the pathways of contemporary as well as historical Estonian polar question particles (PQPs). It will show that not only is the semantic component of function words much more relevant to grammaticalisation than is commonly thought, but also that the grammaticalisation network surrounding a functional category can in fact be semantically so uniform that one can devise a model based on a semantic map and assign it a certain degree of explanatory power regarding why certain markers become PQPs and others are much less likely to do so.
While the most frequently mentioned PQP sources are negation and disjunction markers (Heine & Kuteva 2002), a comprehensive literature review reveals altogether six source categories. In addition to disjunction and negation markers, this list also includes clause conjunction markers, embedded PQPs, conditional markers and pronominal interrogatives (König & Siemund 2007, Nordström 2010, Metslang et al. 2017). These sources appear to form a systematic set – all of the above could be classified as markers of polarity or truth values (see Payne 1985 for coordinators, Nordström 2010 for conditionals). To investigate, whether or not this principle would hold for additional data and other newly discovered source categories, an in-depth corpus study was carried out on Estonian, a language especially rich in both neutral and biased PQPs.
Nearly 2400 polar questions using the particle strategy (inversion and zero-marking strategies are used alongside) were manually encoded in the Corpus of Old Written Estonian (17th–19th century) and the Corpus of Standard Estonian (20th century). I found six different PQPs—four biased and two neutral—used between the 17th and 21st centuries. Three of them—kas, või, ega—are still in use in Standard Modern Estonian. The source of kas is either a clause conjunction (“also”) or an embedded PQP; või most likely originates from a disjunction (“or”); and ega from a clause rejection marker (“nor”). The three historical polar question markers are eks, eps and jo/ju; while the first two originate from negation, the source of the latter is an affirmative focus marker. Only three have given rise to new functional structures: eks became an affirmative polar tag question marker; kas gave rise to the disjunction marker “either”; and jo/ju, after its brief time as a PQP, became a marker of evidentiality when occurring sentence-initially (retaining the older focus reading in other positions).
Hence, the new source categories introduced by the corpus study were polarity-sensitive focus markers (for ju) and rejection markers (for ega), both of which confirm the hypothesis that polar question particles originate from non-interrogative markers, which already involve the semantic component of negation, affirmation or neutral (open) polarity. Table 1 depicts the pathways of Estonian PQPs on a semantic map, which links the two dimensions of polarity – interrogation and bias.
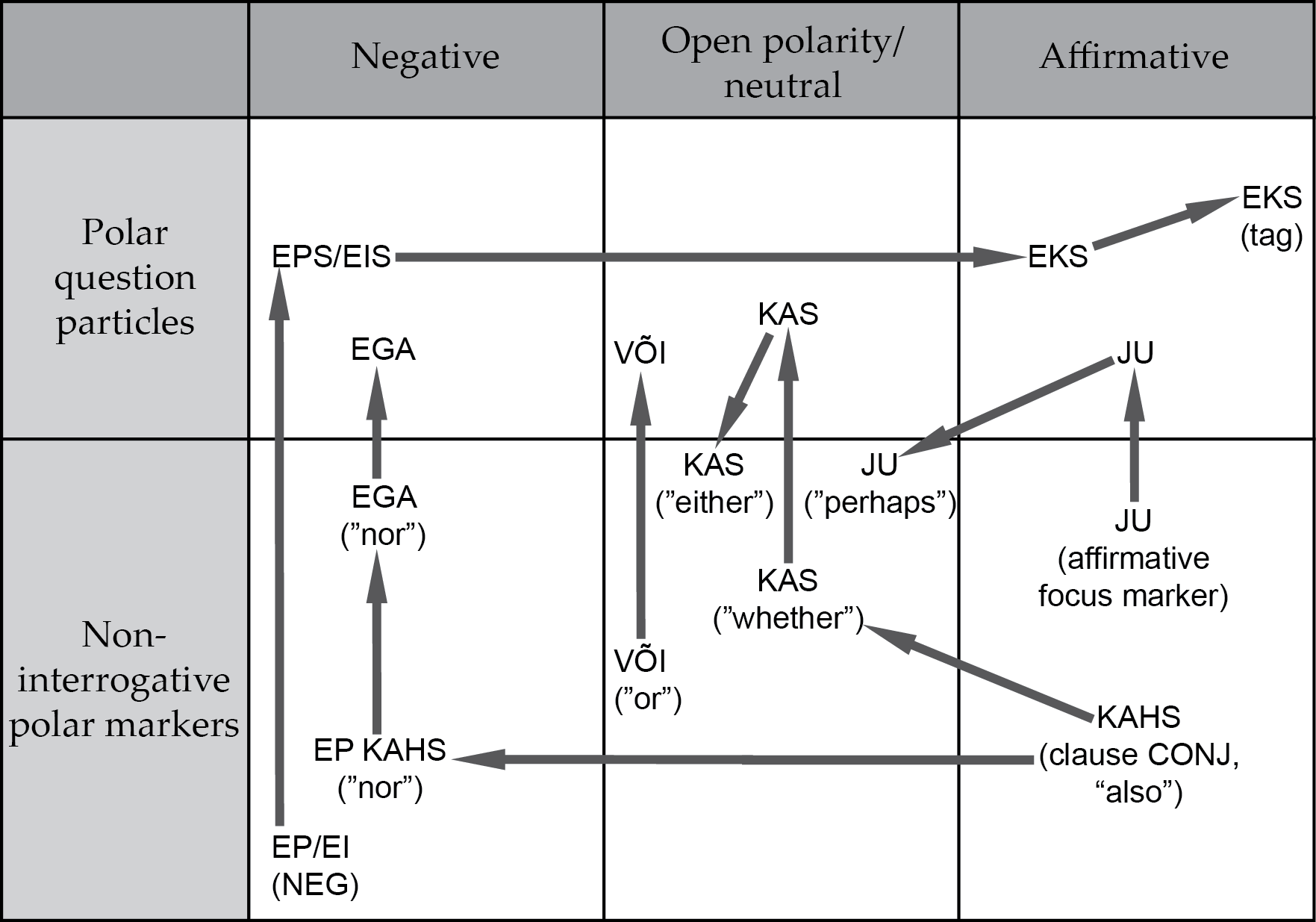
Markers in the neutral category are especially relevant. They leave the truth value unknown, assigning open polarity even without interrogation, and due to this share a close link with PQPs. PQPs are more frequently homophonous with disjunction markers than other particles and both of the non-biased Estonian PQPs, kas and või, originate from the neutral category. Additionally, all functional markers originating from PQPs belong in this category. However, although the fact that the map accommodates all known sources of PQPs implies causality, it can only constitute a probabilistic rather than a deterministic model.
References:
Aigro, M. 2017. A Diachronic Study of Polar Question Particles and Their Sources. MPhil thesis, University of Cambridge.
Heine, B. & Kuteva, T. 2002. World Lexicon of Grammaticalisation, Cambridge: Cambridge University Press.
König, E. & Siemund, P. 2007. Speech Act Distinctions in Grammar. In T. Shopen, ed. Language Typology and Syntactic Description, Vol 1: Clause Structure. Cambridge: Cambridge University Press.
Metslang, H., Habicht, K. & Pajusalu, K. 2017. Where Do Polar Question Markers Come From? STUF – Language Typology and Universals 70(3).
Nordström, J. 2010. Modality and Subordinators, Amsterdam: John Benjamins Publishing Company.
Payne, J.R. 1985. Complex Phrases and Complex Sentences. In T. Shopen (ed.) Language Typology and Syntactic Description. Cambridge: Cambridge University Press.


